Why AI Agents Unlock Software 2.0
In this post I explain why I believe that Andrej Karpathy's vision for "Software 2.0" is finally within reach thanks to AI Agents. Read on to learn more.


I’ve been reading Andrej Karpathy’s Software 2.0 post at least once a year since it came out in 2018. The writing felt so prescient at the time, but I presume it was to be expected from someone working at the edge of the possible with AI.
After so many reads you may believe that I have a full grasp of the topic. But in fact I still believe there is so much to unpack from Karpathy here.
As a refresher, Karpathy stated on his blog that:
The “classical stack” of Software 1.0 is what we’re all familiar with — it is written in languages such as Python, C++, etc. (…)
In contrast, Software 2.0 is written in much more abstract human unfriendly language, such as the weights of a neural network (…) neural networks are not just another classifier, they represent the beginning of a fundamental shift in how we develop software. They are Software 2.0.
Despite this eloquent definition, in my my mind Software 2.0 still felt too abstract and early until recently. The traditional deep learning models, ranging from ConvNets to RNNs did not create as big a paradigm shift as their successor, the large language model (LLM).
And so now in the age of LLMs, I ask this question: what if the true Software 2.0 era was ushered in by AI Agents?
In this post I will share my thoughts on Software 2.0. I will first provide an overview on traditional deep learning. Then I will explain how we got from there to large language models. Finally I will present my thoughts on why I believe agentic systems can realise the promise of Software 2.0 .
The Deep Learning Leap
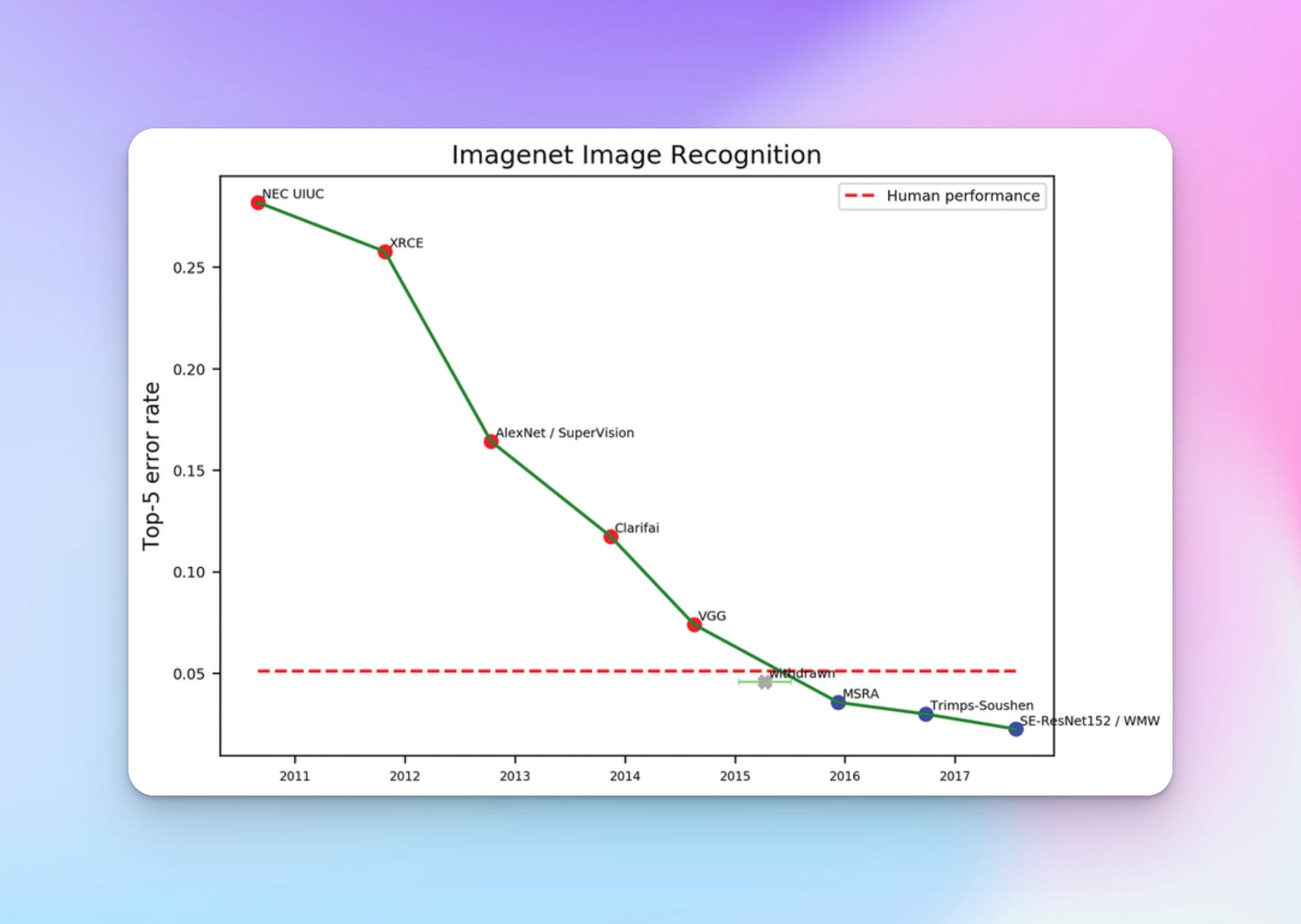
The present AI euphoria we are experiencing has its root in 2012, when AlexNet - a deep learning model - took the Computer Vision world by storm by spectacularly outclassing other entrants in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) contest in 2012.
At the time the ILSVRC was the largest Computer Vision competition in the world. In this contest participants built machine learning models to label images across 1000 categories.

The result of all this, as we recounted a few paragraphs above, is history. AlexNet shocked the world of AI research, and ushered in the current era of deep learning supremacy.
From this point onwards, bigger and more capable deep learning models with innovative architectures vied for the top spot in ImageNet competitions. Since 2016 deep learning models achieve superhuman performance on ImageNet, reaching below 5% top 5 error rate.
In the Natural Language Processing (NLP) world, we also saw the rise of variants of recurrent neural networks like LSTMs, which are a type of deep learning model.
Despite all this incredible progress, grasping the inner workings of these models, and acquiring the know-how to train and fine-tune them still remained a somewhat arcane skill mostly reserved to researchers and machine learning engineers. Most software engineers, while having come across the term “AI”, were not acquainted with deep learning concepts like backpropagation, regularization, or even batch normalization.
AI, while having spread its wings further in the world of software, still remained niche because most of the 100 million software developers across the globe didn’t know how to wield it.
The deep learning tide from the last 10+ years certainly brought software 1.0 forward, but it did not quite get us to Software 2.0 .
But Large Language Models, and the agentic constructs built atop, are showing us a path towards true Software 2.0.
The LLM Revolution
But what are these Large Language Models (LLMs) that have taken the world by storm since OpenAI released ChatGPT in November 2022?
Large Language Models are a type of deep learning model that have been trained on massive amounts of data. While this article’s goal is not to exhaustively cover LLMs in their technical marvel, I feel it is important to understand at a high level what these models are and how they are trained.
LLM Architecture
Most LLMs use as the Transformer as the foundation for their model architecture. The Transformer itself is a novel deep learning model architecture that was invented at Google, and revealed in the seminal paper “Attention is All You Need”. Over time, it became the preferred architecture for deep learning NLP models.

One of the innovations of the Transformer architecture is the massive parallelism that it enables at training and inference time. It is an optimum model architecture that can take advantage of the scalable parallel computation that is made possible on a Graphical Processing Unit (GPU) like NVIDIA’s chips.
Prior to Transformers, it was difficult and time consuming to scale training for RNN/LSTM models due to their sequential nature and unstable computations.

LLMs go further than just adopting the Transformer architecture though. They also innovate in the way they are trained. In fact training for a LLM is generally performed in 3 steps. These steps are Pre-Training, Fine-Tuning, and Reinforcement Learning from Human Feedback (RLHF).
Pre-Training
The goal of Pre-Training is to help the model build a knowledge of our known written world by feeding it massive amounts of data from the web, books, and other written works.
At this stage, the model learns how to predict the next word given the previous words and sentences it has “seen” .
To be more exact, in LLM parlance the unit of computation is not a word but a token. Words are broken down into tokens, which themselves map to vectors of numbers that provide semantic and positional information to the network. These vectors of numbers are commonly referred to as embeddings. These embeddings reside in what we call a latent space, which is a multi-dimensional plane that we humans cannot naturally interpret, but deep learning models can.

Pre-training is critical for LLMs to understand general concepts about our world. Yet with pre-training only LLMs are not very useful conversational assistants.
This is because at pre-training LLMs are only able to predict the next sequence of words given a prior input. For instance if we were to submit to a pre-trained LLM the input “What is your name”, it will likely answer with something such as “How old are you?” or “Where do you live?”. This is because these are generally the type of sequences that follow a question question about someone’s name in the training corpus of an LLM.
In general, we desire the LLM’s output to be aligned with human expectations, so that we may have interactions with it that are more natural, productive, and less harmful.

Instruction Fine-Tuning
With Instruction fine-tuning, we teach the model to respond in ways we would expect a useful assistant to communicate with us. We won’t dive into the technicalities of this step either, but instead we will provide an example, taken from OpenAI’s page on Instruction Following .
For an input prompt such as the following below:
Explain the moon landing to a 6 year old in a few sentences.
The pre-trained GPT-3 model would typically respond with the below sentences:
Explain the theory of gravity to a 6 year old.
Explain the theory of relativity to a 6 year old in a few sentences.
Explain the big bang theory to a 6 year old.
Explain evolution to a 6 year old.
As you can attest, the response given by the model above does not answer our original question. This is because as we mentioned, after pre-training, the model is only guessing what could be plausible follow up words and sentences to our original questions. This is pure next token prediction.
In contrast, after instruction tuning the model would respond with the below to the original prompt:
People went to the moon, and they took pictures of what they saw, and sent them back to the earth so we could all see them.
This is much more aligned with what a human would expect the model to answer.
Therefore, as its name suggest instruction fine-tuning (or simply instruction tuning), is the step through which we instruct the model to follow our instructions conveyed by the prompt. In other words, we are aligning the model’s output with the desired behaviour a human would expect.
RLHF
Reinforcement Learning from Human Feedback (RLHF) is another potential step used during the training phase of a LLM. As we covered earlier, instruction tuning instructs the model on how it should respond to an input prompt (e.g. if the input prompt is a question about X, then the model should respond with answer to the question about X). On the other hand, RLHF trains the model on responding with “best” and “most aligned” answer.
Why do we need RLHF? Hasn’t the model already learned everything relevant through pre-training and then be conditioned to answer in the correct form via instruction fine-tuning?
Not quite.
What if I asked a non-RLHF’ed model “The company didn’t pay me a bonus this year. What should I say to my boss about this matter in our upcoming one-to-one?”, and the model replied: “You should scream to your boss or find dirt on him so that you can use it as blackmail to force them to agree to pay you a bonus”. Since content on the internet can be wild, this could be some of the “knowledge” the model has internalised. In most cases though, this is not what we want, not only because you could end up losing your job or going to prison, but also because it is a morally bad thing to do. In sum, this type of answer is not aligned with what most people would find acceptable.
RLHF teaches the model to adjust its output in order to satisfy a reward model that is designed to penalise outputs which are less aligned with human preferences, and conversely reward outputs that are more aligned with human preferences.
In other words. RLHF helps us incorporate human preferences into the model behaviour to ensure that its responses espouse human values and virtues. In a way, we are imparting our morals to models using RLHF.
Generalisation
LLMs are unreasonably effective at many tasks. Since they generalise so well, they can be used to answer questions, translate, generate text, write code, and more. While they are not true Artificial General Intelligence, they are still the most advanced form of machine intelligence we have on this planet.

One of the other selling points of this technology is that developers can access it via APIs and SDKs. OpenAI, Google, Anthropic, and many other foundation lab and big technology companies serve their LLMs via API. This is in part because many of these models are closed source; so these companies would not make the weights nor model architecture public. And even if the model weights were available (e.g. Llama 3.1), the models themselves would be too costly to run so most companies would not even be able to host and serve them.
Since developers are used to working with APIs, it means that is is very straightforward to interact with a LLM. As a consequence, machine intelligence is now technically available to all developers - just an API call away.
This abundance of machine intelligence has led to an explosion of AI-infused applications. For instance, if you go on Product Hunt nowadays you will see that 80% (or more) of the products being launched have some AI in them.
Software is still eating the world, while AI is eating software.
Limitations
LLMs bring us at the doorstep of Software 2.0, but we can’t yet open those doors with basic LLMs. This is because most interactions with a LLM like ChatGPT are single-threaded conversations which are limited in scope and breadth.
On its own, a LLM may struggle to handle complex tasks if we don’t implement a higher level construct that is capable of handling more complex reasoning and coordination.
AI Agents are this higher level construct.
The Agentic Advent
But what are these AI Agents that may lead us into the promised land of Software 2.0?
To understand what AI Agents are, it is important to start with definitions. Thus, we will first define two related terms: agentic system and then AI Agent.
Definitions
Agentic systems are software architectures that employ one or more AI agents to solve complex problems. These agents work collaboratively by breaking down the problem, executing sub-tasks, reviewing progress and determining if additional steps are needed to achieve the original goal.
Unlike traditional software which is deterministic, agentic systems create dynamic applications with human-like reasoning capabilities.
Now onto AI Agent.
An AI Agent within an agentic system is an instance of a large language model that has been assigned a specific role and given tasks to complete. Completing the task contributes towards the attainment of the overall goal.
For example, in a virtual software development company made up of agents, we could have the following agents:
Product Manager Agent
Developer Agent
Tester Agent
Designer Agent
Each agent would be responsible for specific aspects of the software development process. This multi-agent setup above is similar to the one I covered in my review of the paper ChatDev.

Looking at the diagram above, the key components interacting with an AI Agent are the following:
Prompt/Inputs: these are the instructions given to the agent to complete a task
Memory: this is the internal (by this I mean history) and external knowledge that the agent as access to. External knowledge could be knowledge from documents the agent has access to for instance. In such cases you may use Retrieval Augmented Generation (RAG) to provide the agent with the appropriate knowledge that will help it complete its tasks
Tools are the functions we make available to the agent in order to extend its capabilities
AI Agent is a unit of reasoning backed by a large language model
Result is the output from the agent
I believe that for the first time in history we have through LLMs and AI Agents the ingredients required to approach, and sometimes exceed human proficiency and adaptability at many cognitive tasks.
AI Agent Projects
There is now a rising tide of startups building agents or providing the tools to allow individuals and corporations to do so.
In the former case, you have companies such as Cognition AI, who are building Devin, an advanced AI software developer teammate that uses AI Agents under the hood. CrewAI is another interesting company to follow - they enable developers to run agents on a diverse set of tasks, either via their open-source library or via their premium offering called CrewAI+.
In the latter camp, you may have heard about companies like LangChain which provides frameworks for building and orchestrating agents. On our end, we are also tinkering independently on an open source AI Agent library called Nagato AI to continue exploring this young space.
AI Agents Are Not Perfect
There is a lot of excitement about AI Agents. But there’s also been a fair share of disappointments in the last year. This is because the technology is still unreliable due to the inherent issues of LLMs such as hallucinations, which can compound across multiple calls between agents.
If we are to trust the numbers from WebArena, which is a benchmark for assessment autonomous agents, we can see that humans still overwhelmingly outperform agents in the their leaderboard.

Another issue is speed. Interactions with AI agents generally result in multiple communication turns between agents. Since a single call with an agent itself could take multiple seconds, latency often becomes an issue when multiple agents are involved. This negatively affects user experience, reliability and limits the range of use cases we could employ agents for.
However, I believe the latency issue is currently being addressed. LLM inference providers like Groq enable you to access state-of-art open source models like Llama 3.1 cost-effectively and with blistering speed thanks to their optimised hardware.
Additionally, closed source foundation model companies like OpenAI and Anthropic are hard at work to make their models output tokens at a higher rate per second.
Closing Thoughts
Karpathy’s vision for Software 2.0 was definitely ahead of its time when he published his article. And after a few years of fast progress in the world of AI Research I feel we are finally closing in on this dream.

Deep learning was the right path to take to get to where we are. But deep learning alone via traditional convolutional and recurrent neural networks were only accessible to AI Researchers, ,machine learning engineers, and a fringe of developers and data scientists. This was not true Software 2.0 due to its lack of universality.
LLMs, which are available via APIs, make AI accessible to all. This means any software engineer today - and every smartphone-equipped individual on Earth in the near future - can leverage advanced machine intelligence that would have been considered science-fiction a few years ago.
Unlike in Software 1.0, where we used programming languages such as Python, C++ or Javascript, in Software 2.0 the way we communicate with machines is the same way we communicate among humans: in natural language (i.e. English for most LLMs). LLMs are the gateway to Software 2.0 because of their ubiquity, ability to generalise to a plethora of tasks, and use of English as the primary means of communication with humans.
Yet, LLMs by themselves lack the adaptability or ability to handle long and complex tasks that we humans are good at. AI Agents remedy those deficiencies.
AI agents expand the realm of the possible for LLMs by enabling them to communicate among each other in a deterministic or fully dynamic fashion. Agents allow programs to adapt to unforeseen situations and still solve problems, just like humans are capable of doing. Additionally, agentic systems are able to break down complex tasks and complete each sub-task in order to reach the overarching goal.
AI Agents compound the strengths of LLMs and add resilience and dynamism. Despite their relative newness and reliability issues, they already show promising results. I am confident that the reliability issues we are currently facing with agents will also be addressed over time.
In sum, I am convinced that AI agents are the true medium through which we can achieve Karpathy’s Software 2.0 vision.
The next few years are going to be exciting. Now is the time to build a promising future powered by an abundance of intelligence.
Please share this post if you found it interesting. And if you’re on Twitter/X, then do follow me to read my daily thoughts on AI Agents.
I recently launched Kiseki Labs, a consultancy helping businesses implement GenAI through workshops, strategic advisory, and custom solutions. If you're interested in working together, you can book a free consultation at kisekilabs.com or connect with me on LinkedIn.
Eddie
🙌👌🙌
I can’t tell you how happy I am to have serendipitously come across your writing.
This was incredible.
I immediately subscribed and a huge fan
Thank you
Nix G
Cape Town