Why DeepSeek v3 made such a big splash in the ocean of LLMs
In this post I explain what is DeepSeek v3 and why it is such an important model in the recent history of LLMs.


The biggest AI plot twist at the end of 2024 did not come from Silicon Valley. It unexpectedly came from China. And it is called DeepSeek v3.
Released during the festive period of 2024, DeepSeek v3 is an open-source (open-weights to be more precise) Large Language Model (LLM) that matched the performance of leading closed-source models like GPT-4o and Claude 3.5 Sonnet. It even outperforms them in coding challenges like CodeForces.
What made this release truly remarkable for me wasn't just the technical excellence shown by the DeepSeek team, but how DeepSeek v3 fundamentally challenged everything I previously assumed about the economics of frontier AI model development.
In this post, I’ll cover three key aspects of this groundbreaking development. First, I'll dive deeper into the technical details behind how DeepSeek v3 was trained. Next, I'll explain why I believe DeepSeek’s achievements are crucial for the AI industry. Finally, I'll explore the broader implications and second-order effects that this release could have on AI and geopolitics.
What is DeepSeek v3?
At its core, DeepSeek v3 is a 671B parameter LLM trained on a dataset of 13.8 trillion tokens. It achieved State-Of-The-Art (SOTA) performance, rivalling—and occasionally surpassing—models like GPT-4o and Claude 3.5 Sonnet.
But the true innovation behind DeepSeek v3 isn't just its size. Here are the elements that stood out for me:
Multi-Head Latent Attention
The most important innovation of DeepSeek v3 is arguably its MLA mechanism. MLA stands for Multi-Head Latent Attention. To understand what MLA is and why it's important, we need to first understand the role of the KV cache in the Transformer architecture that powers all SOTA large language models.
LLMs receive tokens – and not words – as inputs, and output tokens in turn. While input tokens can be processed in parallel, output tokens are generally generated sequentially, though techniques like speculative decoding can introduce some parallelism. To generate a single output token, the attention calculations involving all previous input and output tokens need to be performed. If we were to naively perform these attention calculations for each of those tokens for a given output token, then the latency to generate tokens would be very high. Additionally, we would waste precious computation resources performing duplicate work.
That’s where the KV cache comes in. The KV cache simply stands for 'Key-Value cache'. It's a special cache that stores the key and value vectors. These vectors are calculated from the input tokens (or, more precisely, from intermediate representations of those tokens) and are used in the attention mechanism. By storing these key and value vectors, we can reuse the results of previous attention calculations and speed up output token generation.
However, this efficiency comes at a cost: increased memory requirements. This is because the KV cache is stored in the GPU's high-bandwidth memory, which is limited and expensive. As a result, the memory required to store the growing KV cache can become a limiting factor as models process very large input and output token sequences. In this case, we have to employ cache eviction rules and other tricks to manage memory in the KV cache, but this leads to degraded latency in output token generation.
There have been many approaches proposed to address the limitations of the KV cache (e.g., Grouped-Query Attention (GQA), Multi-Query Attention (MQA), etc.), but they all had significant downsides. MLA, however, seems to address the issues with KV cache in an elegant way.
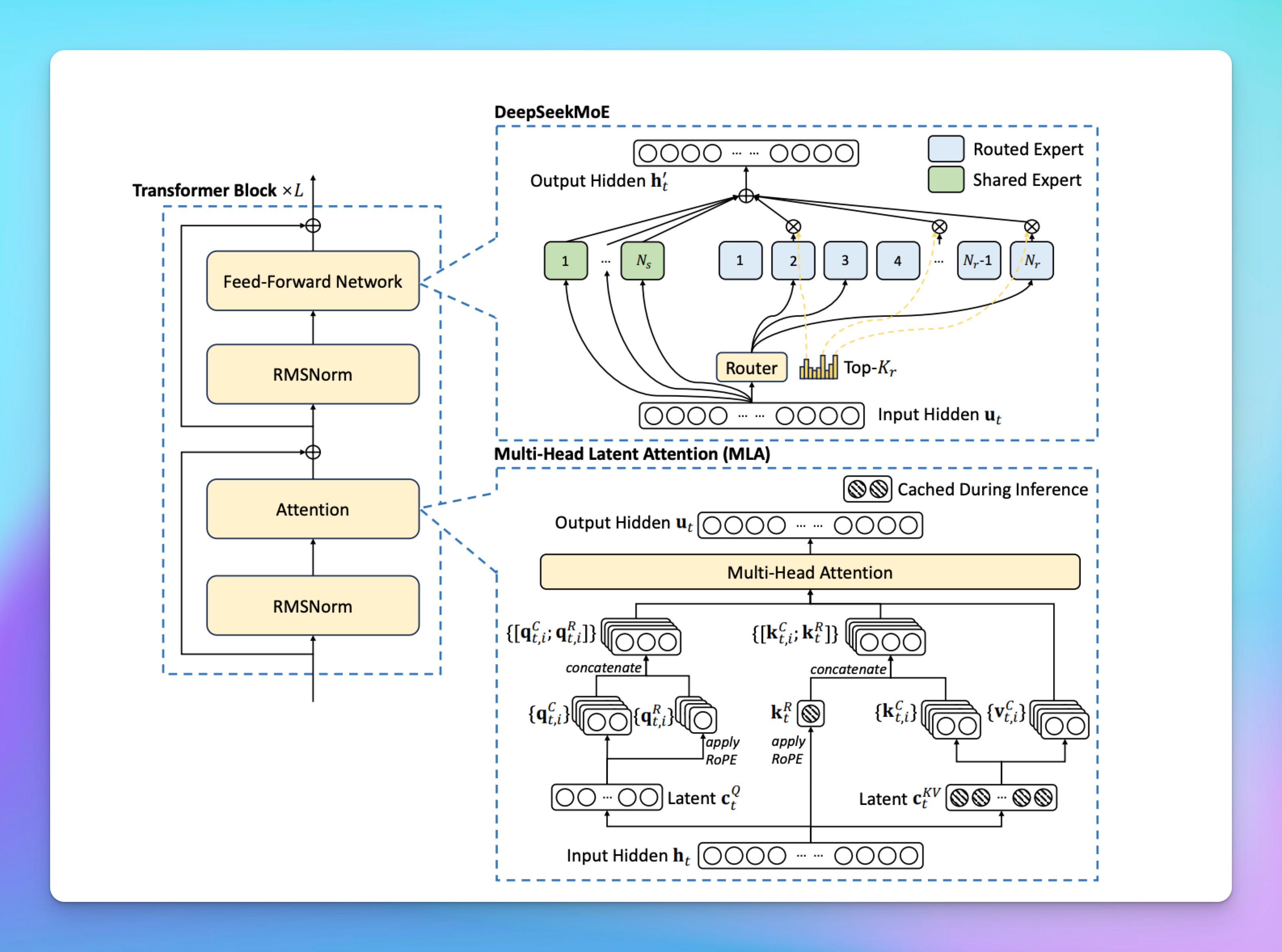
MLA works by compressing key and value vectors into a lower-dimensional space. These compressed vectors are called 'latent' vectors. During the forward pass, the model stores these latent vectors in the KV cache. When generating output tokens, the model retrieves these latent vectors from the cache. Instead of directly reconstructing the original key and value vectors, MLA uses the latent vectors to efficiently perform the necessary computations. This is achieved by merging the operations that would normally use the full key/value vectors with other calculations in the attention mechanism.
t's important to note that MLA doesn't simply 'uncompress' the latent vectors back to their original form. Rather, it leverages them in a different way to achieve the same outcome (attention). This approach retains much of the speed of the original KV cache lookup while addressing the memory limitations, as we can store many more key-value pairs within the compressed latent space.
Mixture of Experts
DeepSeek employs a Mixture of Experts (MoE) architecture with 256 experts. Impressively, the team optimised the model so that only 8 experts (32B parameters) process inputs at any given time, drastically reducing computational costs.
DeepSeek’s specialised expert routing algorithm avoids “routing collapse,” a common issue where certain experts become overloaded, impacting performance negatively. This innovation significantly cuts down training and inference time. It also reduces memory usage.
Multi-Token Prediction
Unlike traditional LLMs trained to predict only the next token, DeepSeek v3 predicts multiple tokens simultaneously during training, using "prediction modules" chained together. This approach enhances the model’s ability to understand longer sequences and dependencies.
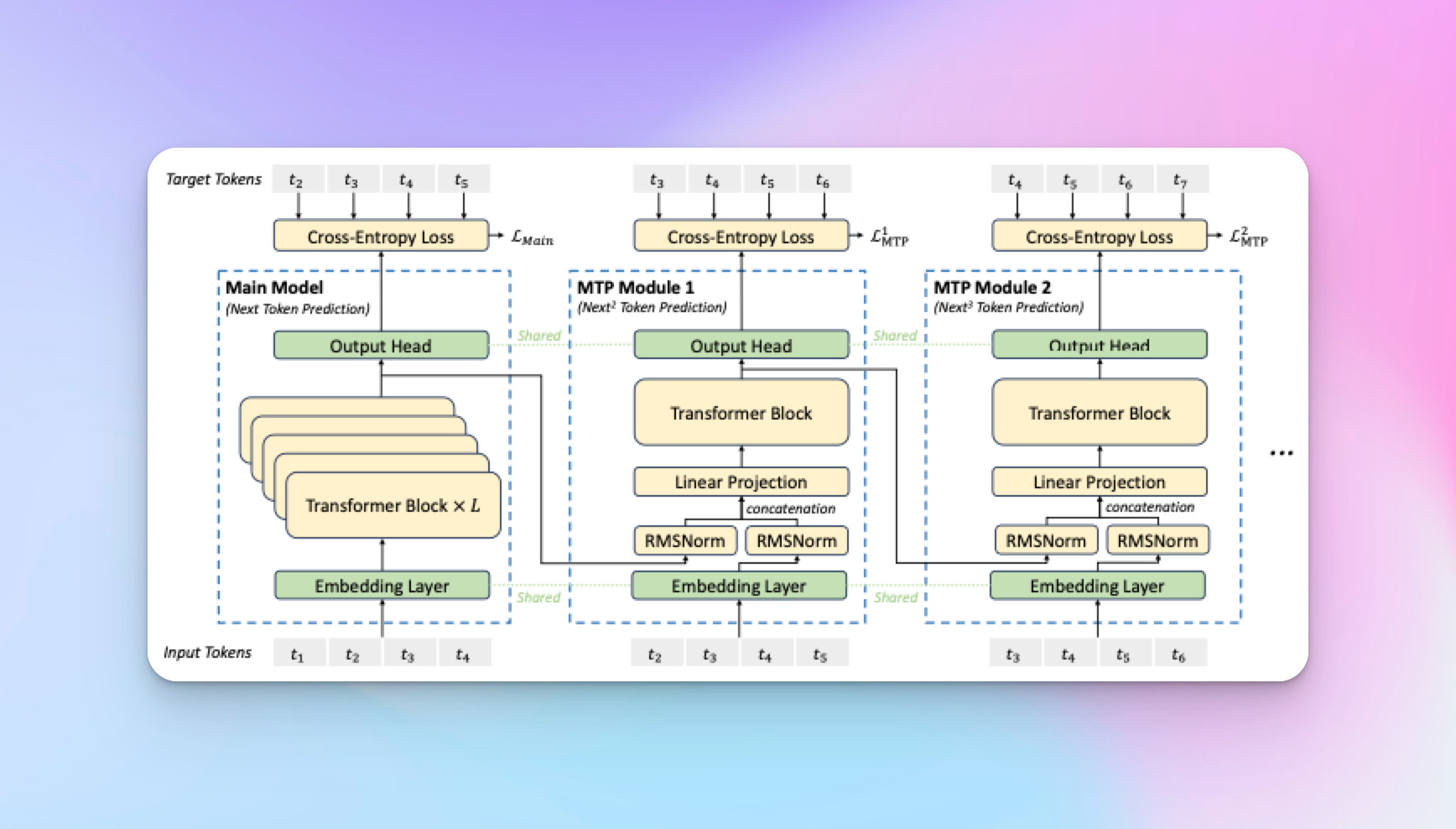
Although MTP was only active during training (predicting two tokens ahead), it helped the model better grasp data structures, thus improving performance. These modules are not used during inference to avoid unnecessary computational overhead.
FP8 Training
DeepSeek adopted an FP8 mixed precision training approach. While FP32 training is common due to numerical accuracy, it's costly computationally. Using FP8 significantly reduced memory and computational demands, though typically at the expense of accuracy.
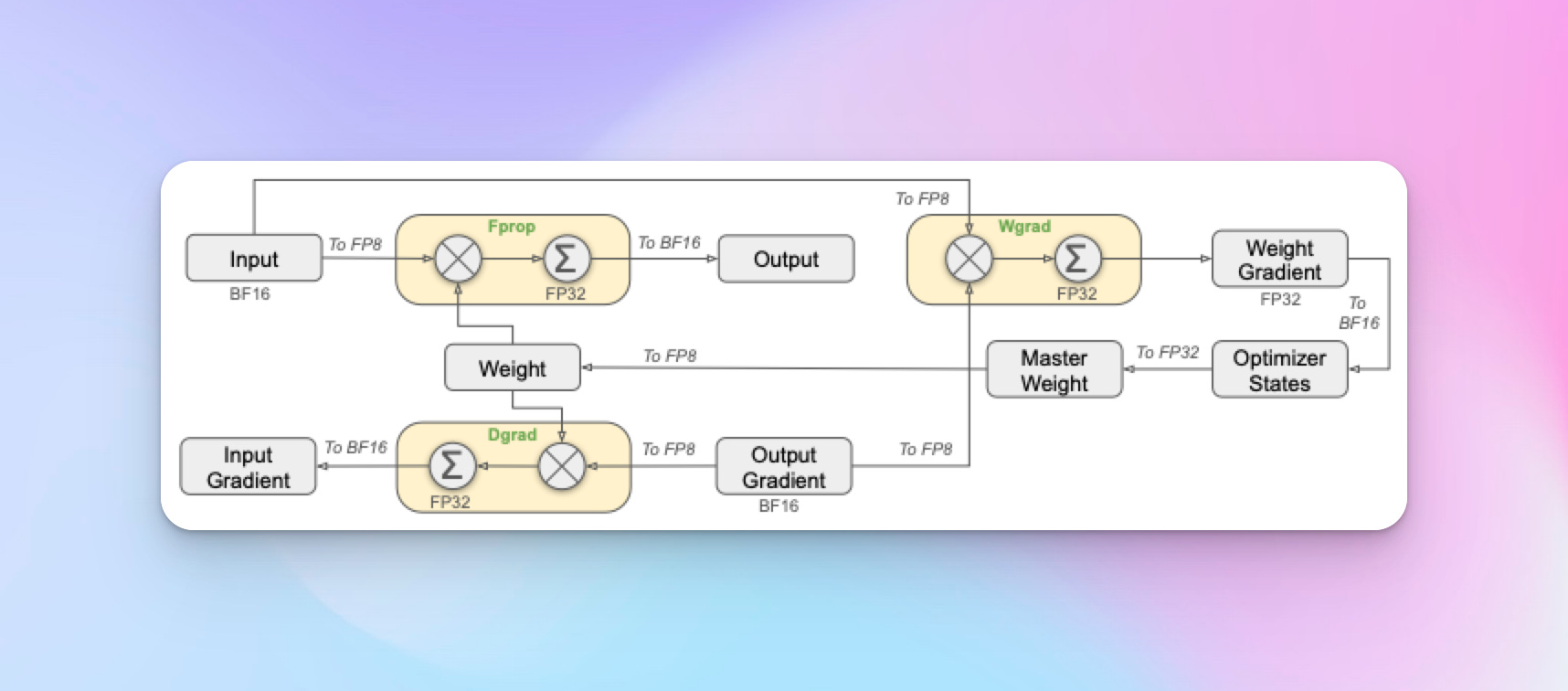
To maintain performance, DeepSeek employed mixed precision, using higher precision in critical parts like embeddings and outputs. They also implemented fine-grained quantization and increased-precision accumulation to ensure numerical stability and maintain high accuracy.
DualPipe Algorithm
The DeepSeek team identified communication bottlenecks during cross-node expert parallelism, which slowed training significantly. To address this, they created DualPipe—a scheduling algorithm for pipeline parallelism.

DualPipe divides and rearranges neural network computations to overlap communication and computation, eliminating significant overhead. This innovative approach reduces "pipeline bubbles," maintaining high efficiency even at scale, enabling quicker training.
Why DeepSeek v3 is a big deal
Faster training cycles
Collectively, these innovations drastically accelerated the training cycle. DeepSeek v3 was trained on just 2,048 NVIDIA H800 GPUs over 57 days, totaling only 2.79 million GPU hours. For comparison, Meta’s Llama 3.1 required 30.8 million GPU hours—11 times more compute—despite fewer parameters.
This shattered my previous assumptions about the immense resources needed for frontier AI model development.
Training costs are 10x lower
According to the DeepSeek team, it only cost $5.6M to train DeepSeek v3. This figure is advanced by the team because they assume a rental cost of $2 an hour per H800 GPU Hour. I wrote above that total training time was around 2.8 million GPU Hours, hence we can derive the $5.6M by doing the simple multiplication 2.8M GPU hour x $2/GPU Hour = $5.6M.
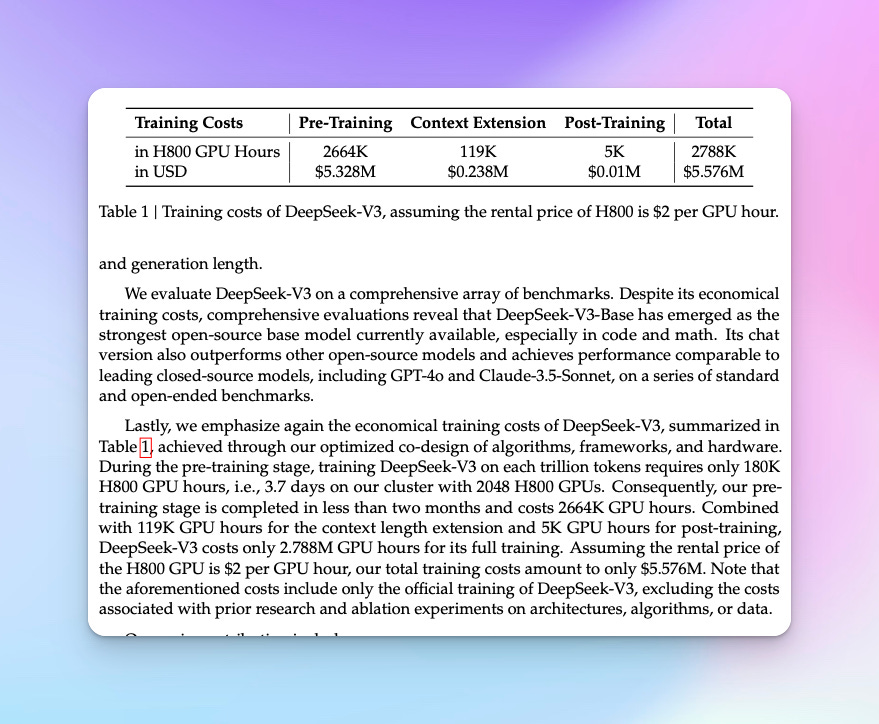
However, I acknowledge this figure excludes broader R&D and personnel costs, meaning actual expenditures are higher. Yet even accounting for these, the economic breakthrough remains undeniable.
A word on H800 GPUs
Let’s revisit the hardware angle again and talk a bit more about those NVIDIA H800 GPUs. American frontier labs typically use NVIDIA H100 GPUs for training loads. H100 GPUs offer higher performance than H800 GPUs due to improvements in memory capacity and compute features. H800 GPUs were designed specifically for the Chinese market to comply with US export restrictions of compute resources to China.
Given this handicap, the achievements from the DeepSeek team are even more commendable. Perhaps more importantly, it proves something that many long suspected: talent and out-of-the-box thinking, and not hardware and compute, are the real limited resources in this “AI Race”.
Second order effects of DeepSeek v3
Democratisation of frontier model development
We’re about to witness a wave of innovation from organisations that previously couldn’t afford to compete because they could not justify compute costs. These organisations won’t be only located in Silicon Valley; research labs and tech companies across the globe, universities, and companies in regions with restricted access to cutting-edge hardware now have the chance to join the frontier of AI development.
All these organisations now have proof via DeepSeek’s achievements that indeed necessity is the mother of invention.
Algorithmic innovations will accelerate
DeepSeek’s breakthroughs will likely trigger more algorithmic innovations designed to overcome traditional scaling laws, pushing the boundaries of what's possible through smarter engineering.
Closed-source models lose their moat
DeepSeek v3 is the perfect counter-argument to those that claim that closed-source labs like OpenAI enjoy a strong moat against open-source models.
It seems from recent examples that the performance from closed frontier models is replicated within 12-18 months. Given these timelines, how can any lab or company maintain a real, long-lasting advantage?
Accelerated frontier model development
We’re likely to see an acceleration in the development of frontier models. Since DeepSeek’s innovations are now available to all, I expect leading and closed source frontier lab organisations to incorporate them into their training methodology.
These techniques have the potential to bring down the time it takes to train SOTA models. This means that AGI and ASI timelines could be brought forward.
Conclusion
DeepSeek v3 represents much more than another large language model. It is instead a revelation and a wake up call for the entire industry. It shows that open-source AI development can bring the industry forward. This is exactly what Mark Zuckerberg advanced when he wrote that Open Source AI is the Path Forward in the summer of 2024.
For technologists like myself, DeepSeek v3 is proof of how clever engineering and innovation can outperform brute computational power. In one sentence: this team have significantly raised the bar for the entire industry.
The DeepSeek team have also recently upped the ante by releasing DeepSeek R1, a reasoning model that is on par with OpenAI’s o1 model. R1 is another groundbreaking model which deserves a separate post from me in the future.
You can try DeepSeek v3 yourself via web chat or API at a fraction of the cost of models like Claude 3.5 Sonnet or GPT-4o.
I recently launched Kiseki Labs, a consultancy helping businesses implement GenAI through workshops, strategic advisory, and custom solutions. If you're interested in working together, you can book a free consultation at kisekilabs.com or connect with me on LinkedIn.